
Robot.txt文件是什么?
Robots.txt 是一个位于网站根目录的纯文本文件,用于告诉搜索引擎爬虫(如Googlebot、Baiduspider)哪些页面可以抓取,哪些页面不允许抓取。它是**爬虫协议(Robots Exclusion Protocol, REP)**的一部分,帮助网站管理员控制搜索引擎对网站的访问权限。
Robot.txt文件对SEO的重要性
(1) 提高爬取效率,优化抓取预算 (Crawl Budget)
搜索引擎每天对网站的抓取资源是有限的,如果浪费在不重要的页面上(如后台、日志文件、重复页面),可能会导致重要页面得不到及时抓取。而且,现在随着AI的出现,页面内容呈现爆炸式增长,谷歌数据库其实早已不堪重负!如果你不能很好地引导Google Bot在你网站进行抓取收录,那么很有可能你页面迟迟不被收录,尤其是对于新站点而言!
(2) 防止搜索引擎抓取重复或低质量内容
网站可能会生成大量重复页面或低质量内容,如果这些被索引,可能会影响网站的 SEO 评分。举个例子,tag标签,尽管有部分认为tag标签是一个可以单独优化的内容,当目前对于大部分外贸跨境网站的SEO实操来说,其实根本没有必要去设置tag标签,其唯一的作用也就是导航了,但是由于tag标签和catagories存在许多类似性,因此会重复,假如出于用户友好性,你的网站确实想要保留Tag标签,又不想其被收录,那么最好的方法就是在Robot.txt中写明让google bot 不收录tag标签页面。
(3) 保护敏感数据,防止隐私泄露
网站的后台管理、用户信息、数据库、插件数据等,不应该被搜索引擎爬取。这些是非常重要的,举个例子,以我自己的亲身经历,曾经就出现因为插件漏洞被黑帽SEO劫持快照,导致网站被收录了大量黑帽SEO植入的垃圾页面,对网站的影响不可为不小!而这一切的原因是什么呢?我所安装的某些网站优化插件有隐私泄露的bug,正好被搜索引擎抓取到了,然后黑帽SEO通过搜索引擎抓取全网寻找BUG,一抓一个准,于是乎我的网站就被黑了!
(4) 引导爬虫优先抓取核心内容
有些页面对于 SEO 非常重要,如产品页面、博客文章、服务页面, XML 网站地图等。通过 robots.txt,可以确保爬虫优先抓取重要页面,提高排名机会。
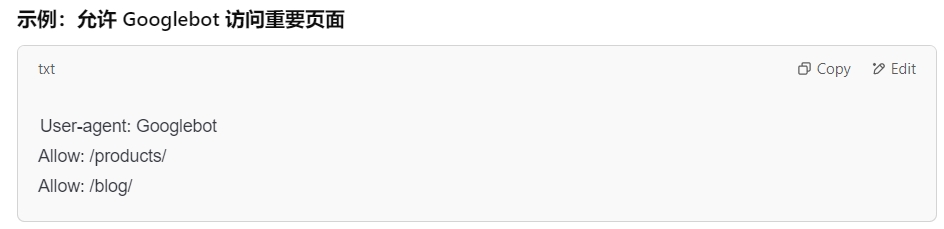
如何一步步设置你的Robot.txt文件?
因为目前建站B2B主要是Wordpress,而B2C主要是Shopify,因此我将分两个平台来逐一介绍一下Robot.txt在各自平台如何去设置构建。
WordPress 站点 Robots.txt 设置流程
WordPress 默认会生成一个虚拟的 robots.txt 文件,但你可以手动编辑它,优化搜索引擎抓取。
方法 1:使用 Yoast SEO 插件(推荐)
- 安装 Yoast SEO 插件
- 在 WordPress 后台插件 > 安装插件,搜索 Yoast SEO 并安装。
- 启用插件。
- 进入 Yoast SEO 设置
- 在 WordPress 后台,进入 Yoast SEO > 工具。
- 选择 文件编辑(如果没有这个选项,可能是服务器权限问题)。
- 修改 robots.txt
- 进入 robots.txt 编辑器,添加或修改内容。
- 保存更改
方法 2:手动上传 Robots.txt
1、创建 robots.txt 文件
- 使用 记事本(Windows) 或 TextEdit(Mac) 创建一个新文件,命名为
robots.txt。 - 添加你的规则,例如:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://www.example.com/sitemap.xml2、上传至 WordPress 根目录
- 通过 FTP 工具(如 FileZilla) 或 cPanel 登录你的 WordPress 服务器。
- 找到
public_html/或www/目录。 - 将
robots.txt上传到该目录。
3、测试 robots.txt 是否生效
Shopify 站点 Robots.txt 设置流程
Shopify 默认自动生成 robots.txt,但你可以通过 Shopify 的代码编辑器手动修改它。
1、进入 Shopify 后台
- 登录 Shopify 管理面板。
- 点击 在线商店 > 主题。
2、编辑 robots.txt 文件
- 在当前主题的 “编辑代码” 页面,找到 robots.txt.liquid(Shopify 允许编辑这个文件)。
- 修改或添加规则(如允许爬取某些页面或屏蔽无价值页面)。例如,如果你不希望搜索引擎索引
collection过滤页面:
User-agent: *
Disallow: /collections/*?*3、保存并发布
Robot.txt的通用格式
这里我分为三种格式,一种是B2B和B2C通用,另一个专门针对B2B的wordpress网站,最后一个专门针对B2C的shopify网站.
B2B和B2C通用
# 通用设置
User-agent: *
Disallow: /cart/
Disallow: /checkout/
Disallow: /order/
Disallow: /my-account/
Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
Disallow: /wp-includes/
Disallow: /cgi-bin/
# 允许访问 WordPress 必需的资源
Allow: /wp-admin/admin-ajax.php
# 允许搜索引擎访问 Shopify 产品和目录页面
Allow: /collections/
Allow: /products/
# 对 WordPress 网站设置特定的 Disallow 规则
Disallow: /author/
Disallow: /category/
Disallow: /tag/
Disallow: /archives/
Disallow: /search/
# 允许访问 Shopify 主题和资源文件
Allow: /assets/
Allow: /files/
# 通用对 Sitemap 的指示
Sitemap: https://www.yoursite.com/sitemap.xml
WordPress的Robot.txt
# 通用设置
User-agent: *
Disallow: /wp-admin/ # 禁止抓取WordPress后台管理界面
Disallow: /wp-login.php # 禁止抓取WordPress登录页面
Disallow: /wp-content/ # 禁止抓取WordPress内容文件夹(避免抓取插件和主题代码)
Disallow: /wp-includes/ # 禁止抓取WordPress核心文件
Disallow: /cgi-bin/ # 禁止抓取CGI脚本文件夹
Disallow: /trackback/ # 禁止抓取Trackback链接
Disallow: /tag/ # 禁止抓取标签页面,防止关键词滥用
Disallow: /search/ # 禁止抓取搜索结果页面,避免重复内容被索引
Disallow: /comments/ # 禁止抓取评论页面
Disallow: /xmlrpc.php # 禁止抓取XML-RPC接口,避免滥用
# 保护隐私,避免抓取用户信息
Disallow: /my-account/ # 禁止抓取用户账户页面
Disallow: /cart/ # 禁止抓取购物车页面
Disallow: /checkout/ # 禁止抓取结账页面
Disallow: /order/ # 禁止抓取订单页面
# 允许抓取需要索引的内容
Allow: /wp-admin/admin-ajax.php # 允许抓取WordPress后台的AJAX处理文件,用于正常前端交互
# 防止黑帽SEO滥用搜索功能
Disallow: /?s= # 禁止抓取带有搜索参数的页面,避免搜索页面被滥用
# 禁止抓取特定内容,如临时或重复页面
Disallow: /?page_id= # 禁止抓取带有page_id参数的页面,避免重复内容被抓取
Disallow: /?replytocom= # 禁止抓取评论回复页面,避免重复内容
# 允许抓取有用的内容
Allow: /wp-content/uploads/ # 允许抓取上传的媒体文件夹,确保图片、视频和PDF等内容能被搜索引擎抓取
Allow: /wp-content/themes/ # 允许抓取主题文件夹(只限于已启用的主题,避免抓取不必要的文件)
# 站点地图设置,帮助搜索引擎更好地抓取站点
Sitemap: https://www.yoursite.com/sitemap.xml
Shopify的Robot.txt
# 允许所有用户代理抓取站点
User-agent: *
Disallow: /admin/ # 禁止抓取Shopify后台管理页面
Disallow: /cart/ # 禁止抓取购物车页面
Disallow: /checkout/ # 禁止抓取结账页面
Disallow: /orders/ # 禁止抓取订单页面
Disallow: /account/ # 禁止抓取账户页面(保护用户信息)
Disallow: /collections/*/filters # 禁止抓取带有过滤参数的集合页面,避免重复内容和无用抓取
Disallow: /search/ # 禁止抓取搜索结果页面,避免低质量内容和重复页面
Disallow: /blogs/*/comments # 禁止抓取评论页面,避免评论内容被抓取
Disallow: /thank_you/ # 禁止抓取订单完成后的感谢页面
Disallow: /gift_cards/ # 禁止抓取礼品卡页面
Disallow: /tracking/ # 禁止抓取快递追踪页面
# 防止黑帽SEO滥用和恶意抓取
Disallow: /?sort= # 禁止抓取带有排序参数的页面,防止排序被滥用
Disallow: /?filter= # 禁止抓取带有筛选参数的页面,防止筛选被滥用
Disallow: /?page= # 禁止抓取分页参数,避免分页页面被滥用
# 允许抓取重要内容
Allow: /assets/ # 允许抓取Shopify站点中的静态资源(如图片、CSS、JS文件)
Allow: /sitemap.xml # 允许抓取站点地图文件,帮助搜索引擎更好地理解站点结构
Allow: /product/ # 允许抓取商品页面,确保商品能够被索引
Allow: /collections/ # 允许抓取集合页面,帮助商品分类被索引
# 保护隐私和防止敏感信息泄露
Disallow: /password/ # 禁止抓取密码保护页面
Disallow: /secure/ # 禁止抓取敏感页面,确保支付和交易安全
# 站点地图设置
Sitemap: https://www.yoursite.com/sitemap.xml # 添加站点地图URL,帮助搜索引擎更高效地抓取网站如何检测Robot.txt设置是否成功?
方法 1:直接在浏览器检查
- 在浏览器地址栏输入:
https://www.yourwebsite.com/robots.txt
方法 2:Google Search Console 测试
- 进入 Google Search Console(https://search.google.com/search-console)
- 选择你的网站,进入 抓取 > robots.txt 测试工具。
- 输入 URL 进行测试,Google 会告诉你是否正确。
其他建议
除了 robots.txt,还可以用 meta robots 标记: 如果页面已经被 Google 收录,你还需要在 <head> 添加:
<meta name="robots" content="noindex, follow">

